



What is Machine Learning?
Machine learning (ML) is a branch of artificial intelligence (AI) that allows systems to learn and deliver insights without being explicitly programmed on how to do so. It typically uses sample data to learn and develop predictive analysis algorithms. Unlike statistical models, ML technology has an iterative learning process where the computer is nudged into finding a structure in the data set without having a necessary theoretical background. If you throw images of cats and dogs into an ML system, it could potentially separate the images of cats and dogs without knowing the actual differences between them. Hence, it learns from data and experience to improve performance.
Most companies that work with big data use various machine learning algorithms. Industries like healthcare, financial services, governments, transportation services, and many others rely on it to get real-time insights and gain an advantage over their competitors. The most well-known machine learning applications are the decision-making algorithms for Netflix and Amazon recommendations, self-driving cars, and speech recognition.
ML falls within the broader realm of AI. AI includes all computer systems that are involved with imitating human intelligence. These can be tasks like understanding natural language, interpreting images, and other cognitive tasks.
Deep learning is a part of supervised machine learning that uses structured and unstructured training data in neural network (NN) algorithms to make predictions the same way a human brain does. Any NN with more than three nodes or layers through which data is processed is usually considered a part of deep learning.
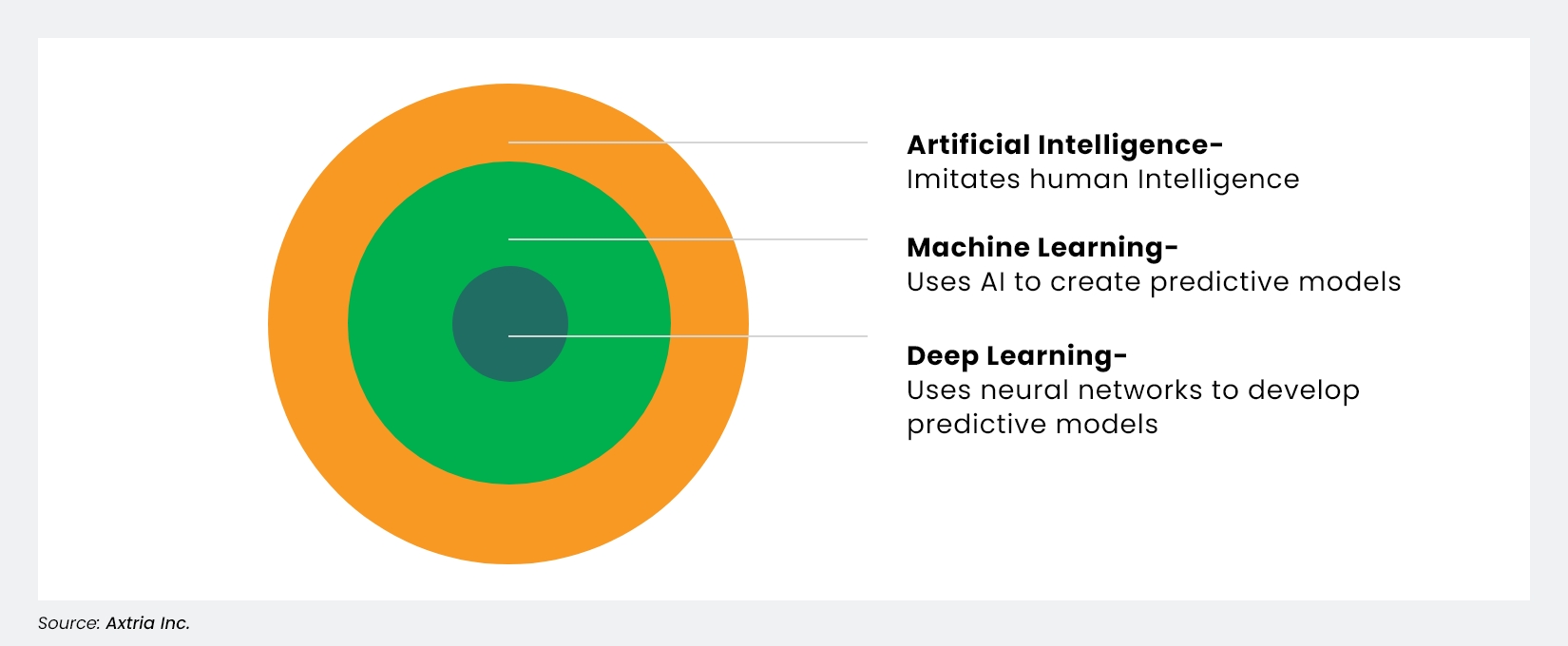
Figure 1: AI vs. ML vs. DL
How does Machine Learning Work?
Machine learning algorithms or models are systems developed through iterative learning. The learning process usually involves feeding the machine a certain amount of data, usually with corresponding outcomes or labels, and then using mathematical optimization algorithms to adjust the model's parameters to make accurate predictions about new, unseen data.
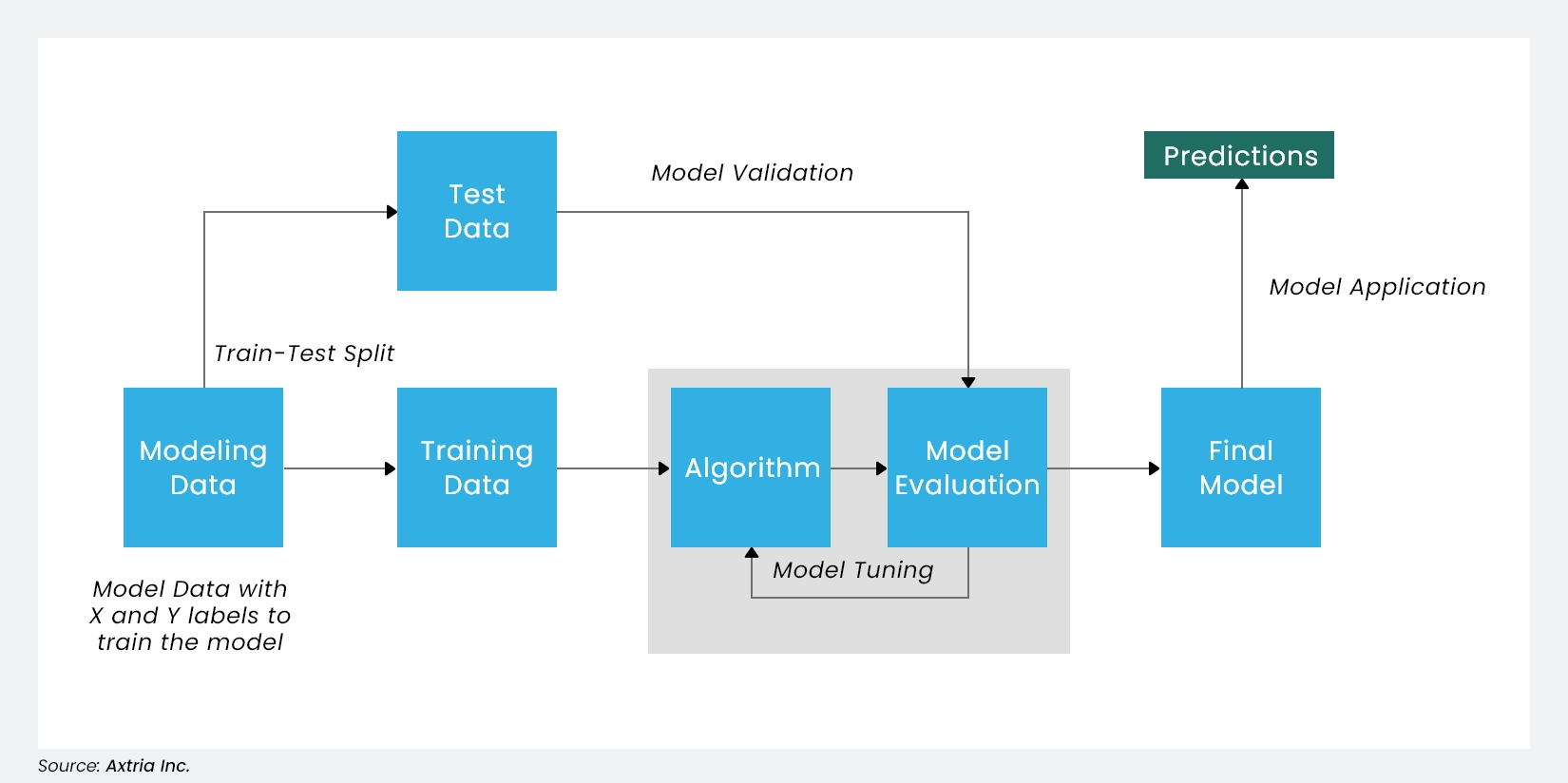
Figure 2: Overview of the Machine Learning Model
Types of Machine Learning
Machine learning algorithms are often classified into three categories: supervised, unsupervised, and reinforcement learning.
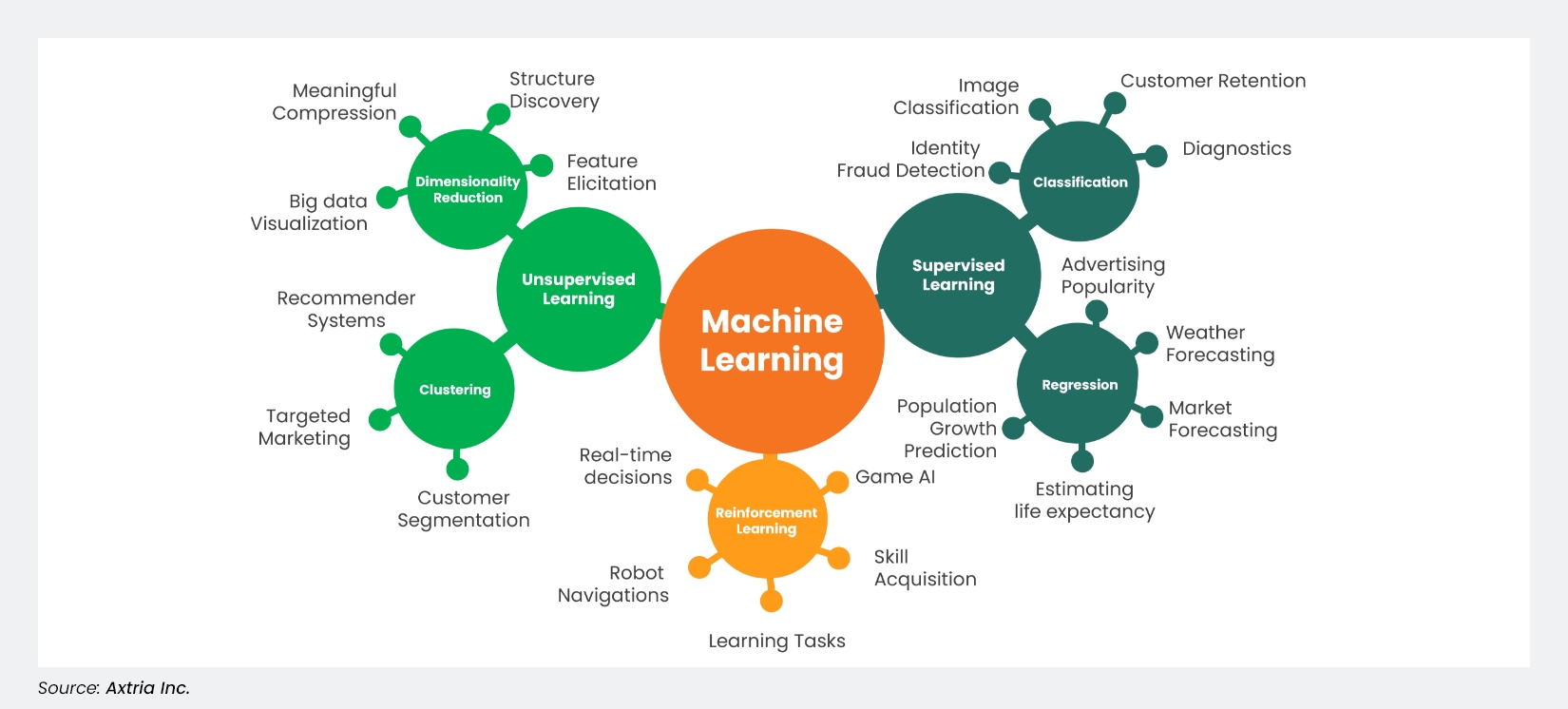
Figure 3: Types of Machine Learning
In supervised learning, we know a relationship exists between the input and the output before we give a data set to the algorithm. We know what our correct output should look like—for example, by feeding labeled images of cats and dogs to the algorithm, we expect the algorithm to learn how the features of a cat and dog are different. A trained algorithm should then be able to distinguish a new image of a cat from that of a dog.
In unsupervised learning, there is no known output. The algorithm is asked to extract some structure from the input data. For example, a collection of 1,000,000 different genes can be fed into an ML algorithm and the algorithm could end up grouping similar genes based on features such as lifespan, location, roles, and so on.
With reinforcement learning, the algorithm learns what to do and how to map situations to actions. The algorithm is not told which action to take but, through constant feedback, must discover which one will yield the maximum reward. The algorithm learns to perform a task simply by trying to maximize the rewards; for example, it can maximize the points it receives for increasing an investment portfolio's returns.
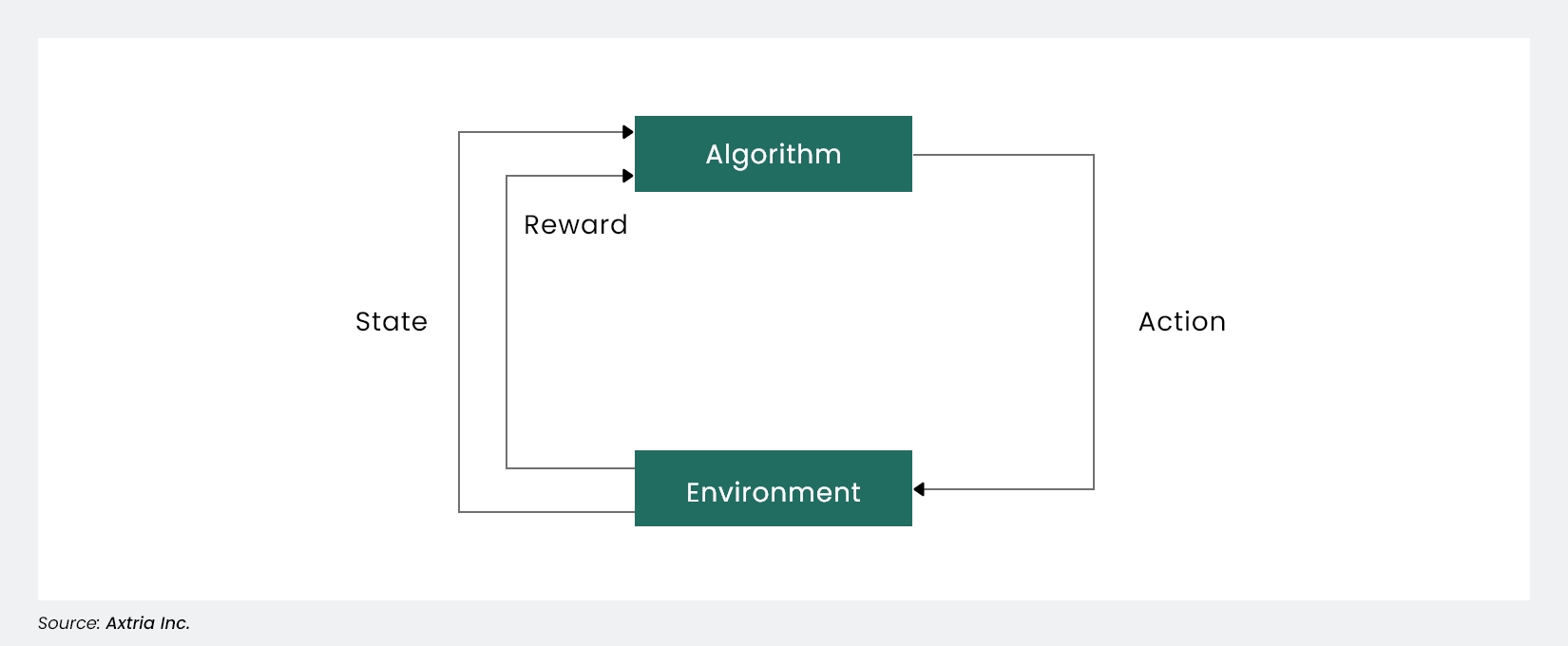
Figure 4: Reinforcement Learning Algorithm
Machine Learning Algorithms
Supervised and unsupervised learning can be divided further. Supervised learning algorithms may be considered regression or classification algorithms based on whether the output variable is real/continuous or discrete/categorical, respectively. Similarly, unsupervised learning algorithms can be clustering or dimensionality reduction. We use clustering to break down a set of observations into similar groups based on patterns in the data. In dimensionality reduction, relationships among all variables are analyzed and weeded down to find the ones that retain as much information as possible, simplifying the model.
A brief overview of some popular ML algorithms follows:
Linear Regression is a supervised ML method that maps the relationship between an output variable (also known as a dependent variable) and multiple input variables (also known as independent variables). It uses labeled training data to calculate coefficients for a linear equation. Linear regression is used in finance and marketing for forecasting and trend analysis due to its simplicity and effectiveness in supervised regression learning.
Logistic Regression is a statistical method used to analyze a dataset and predict binary outcomes with given independent variables. It provides an outcome's probability and odds, making it easy to interpret and implement. It is helpful for binary and multi-class classification problems. It is a variation of linear regression, with the dependent variable limited between the values of 0 and 1 using a logistic function.
Decision Trees are popular ML techniques used for modeling decision-making processes. Decision trees construct a tree-like graph to predict outcomes based on input features through recursive data splitting, resulting in a set of decision rules. They are simple and easily interpretable.
Random Forests are an ensemble ML technique wherein several decision trees are aggregated, and the mode or mean prediction is provided as an output, depending on the problem statement. They provide more balanced, averaged results, are fast and scalable, and can handle categorical variables, missing values, and outliers in the data.
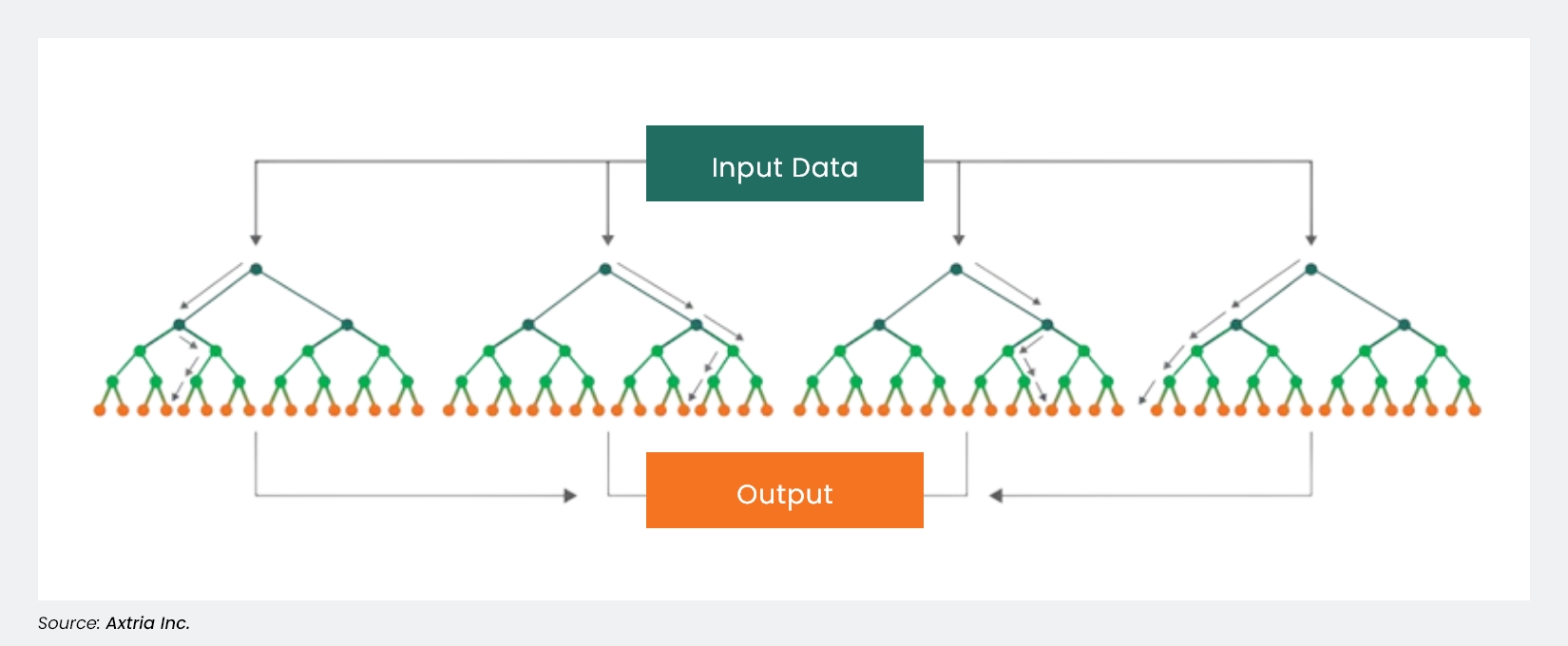
Figure 5: The random forest ML technique
Neural Networks are advanced machine learning algorithms modeled after the human brain's structure and function. These powerful algorithms can be trained, either supervised or unsupervised, depending on the task requirements and available data. A neural network is an extensive collection of unique interconnected equations that all work together to provide different parts of a final combined prediction. Their success has been demonstrated across various tasks, including image classification and natural language processing (NLP), and gaming.
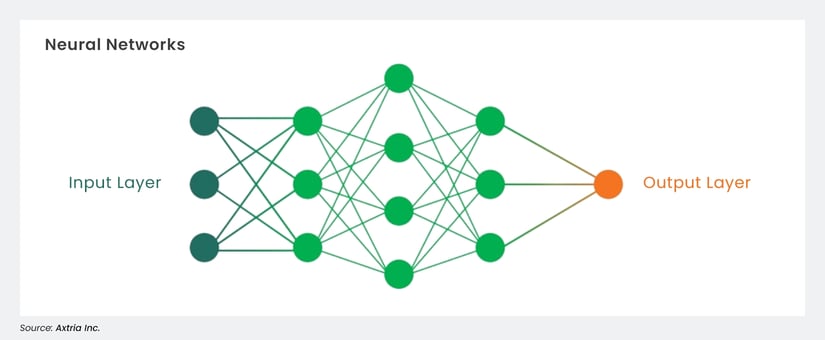
Figure 6: Neural Networks
K-Means Clustering is an unsupervised ML method that first groups similar data points into clusters. Each cluster's center (or "centroid") represents the mean value of all points in that cluster, and k represents the number of clusters you need. This method then assigns each data point to its nearest centroid based on similarity and improves iteratively by calculating the new centroid as the mean of each class.
Principal Component Analysis is an unsupervised ML algorithm that discovers the relationships between variables and reduces the variables down to uncorrelated features (also called principal components) that embody a dataset's vital information with redundancy, noise, and outliers stripped out.
How to Create Good Machine Learning Models
Creating any machine learning model is usually dictated by the problem statement at hand. The kind of data available, the amount of data available, and the algorithm being used are some of the fundamental aspects that will define how good the models are. However, creating good machine learning models is an art, and any data scientist can practice a few steps to ensure they produce the best possible model within the constraints.
- Understanding the model objective: At the very outset, it is imperative to have a crystal-clear understanding of how ML will help solve the problem statement. Does the problem statement need prediction? Is there an objective variable to predict? How frequent will the forecasts be? These are some of the questions that can provide clarity on the kind of model to create.
- Choosing an appropriate algorithm: Once the ML approach is finalized, the right algorithm can make all the difference in how good the model will be. If there is no objective variable, can we adopt an unsupervised approach? If supervised, is the objective variable linear or categorical? Is there enough data available, or do we need to choose the best ML model for sparse data? The problem could also demand a learning-by-trial approach using a reinforcement learning algorithm.
- Data preparation: The available dataset(s) must be validated for completeness. For supervised approaches, both labeled and unlabeled features should be present. For unsupervised, only the latter would suffice. Outliers, missing values, and relevance of features must be evaluated before applying any algorithm to the dataset.
- Cross-validation: A good machine learning model should be able to generalize and make relevant predictions on arrays of data points. Cross-validation is one technique that can be applied during model training to test the generalization of the model predictions. This approach tests the model performance on random partitions of the dataset and ensures that the model's performance is not limited to any biased data partition.
- Tuning the model: Most ML algorithms have a range of parameters and hyperparameters that can be tweaked or altered. The model performance varies with these tweaks and can significantly improve the accuracy metrics. Optimizing the parameters or hyperparameters using random or grid search approaches can substantially affect the ML models' performance.
Machine Learning Applications
Many organizations, industries, and services use machine learning algorithms to produce predictions, analyses, and insights that increase productivity and improve workflows.
Some of the real-world applications include:
- Pattern recognition: ML algorithms recognize and understand patterns by gathering statistical information during their analyses. Examples include linear and logistic regressions, deep learning, and fuzzy-based algorithms. Pattern recognition is used for image, facial, fingerprint, speech, and speaker recognition, among many other applications.
- Text-to-graph machine learning: Text-to-graph machine learning is an application of pattern recognition that can create graphs from text structures. It is a part of NLP that allows machines to process language in the same way as humans. The algorithm can use unstructured data to derive results.
- Chatbots: AI models can develop programs that allow people to receive answers to any form of question. ML algorithms use data and NLP to build communication between computers and humans. Companies use chatbots to increase sales performance and improve customer service. Open-source platforms like ChatGPT are a huge step in that direction. For example, ChatGPT uses a deep learning neural network that allows data from the internet to predict the text and provide a meaningful output to a user for any query.
- Self-driving cars: Machine learning algorithms allow cars to collect data about roads, vehicles, and traffic signals from their immediate surroundings and use it for interpretation and decision-making. Multiple ML applications like image processing, reinforcement learning, and pattern recognition run concurrently to enable real-time decision-making.
Machine Learning in Healthcare
- Patient Treatment Pathways in the Healthcare Sector: Machine learning is used extensively by healthcare industries to provide the most accurate diagnoses and best possible treatment solutions to patients. One example of machine learning in the healthcare industry is the creation and analysis of patient journeys. Real-world data on patients and their treatment journeys is becoming increasingly vast and complex. Machine learning algorithms process this data and deliver insights and health outcomes that are more accurate and relevant.
- Medical Imaging: Accurately labeled and annotated medical images can be used as training data for ML models to derive diagnostic and other medical results. Properly trained ML algorithms can assist in clinical decision-making and screen for injuries and other medical abnormalities. Algorithms like convolutional neural networks can use patients' procedural tests and images to help physicians understand related diagnoses.
- Content Optimization for Healthcare Practitioners: In the healthcare industry, the real influencers are the healthcare practitioners. Proper communication can help them build an informed opinion of new drugs, safety issues, side effects, patient care programs, nurse care programs, and co-pay offers. ML algorithms can help field reps determine the right content for every HCP interaction. Based on the HCP's preferences, an ML algorithm can suggest which promotional content will help the HCP make the most informed decisions.
The Future of Machine Learning
Machine learning has a promising future in healthcare. It will revolutionize how medical problems are diagnosed, treated, and prevented. In the coming years, it is expected to be increasingly important in personalized medicine, disease diagnosis and prognosis, drug discovery, and clinical decision-making. Integrating machine learning algorithms with electronic health records and wearable devices will lead to more accurate and efficient healthcare services. Machine learning can also identify potential health risks, improve population health management, and support healthcare providers in making more informed treatment decisions. However, addressing concerns around data privacy, ethical considerations, and potential biases in the training data will be essential to ensure these technologies are used responsibly and effectively.
Conclusion and Takeaways
Machine learning has had the analytics field buzzing for the past few years, and that buzz will not stop soon. The distinct factor about machine learning is that it is ever-expanding with new algorithms, optimizations, and efficiencies, such as the new visual tools found in Dataiku, KNIME, and Alteryx, which have taken the field by storm. These tools remove the traditional need to know Python R code for creating models. They allow easy drag-and-drop options for creating advanced ML models. However, there is no substitute for understanding the requirements, applying a suitable algorithm, and translating the analytical model into a business solution. As data scientists, we must endeavor to understand the world of machine learning, from the basics to the most intricate algorithm, and do our best to keep up with the changes the future holds.
This article is contributed by Prakash Singh, Senior Manager at Axtria.