-
Products
-
Product Portfolio
-

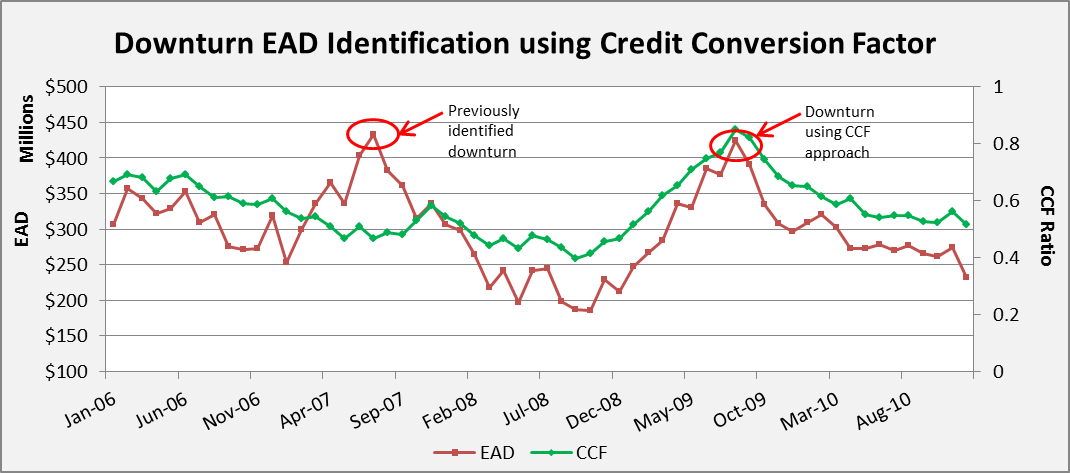
Accelerate actionable business insights from trusted and secure data
-

Enterprise-grade insights for emerging pharma
-

Agentic AI Life Sciences platform with 30+ agents for deployment and experimentation
-

Optimize sales team customer engagement and drive higher commercial success
-

Leverage next best action (NBA) driven omnichannel customer engagement
-

Democratize marketing analytics to achieve strategic performance
-
-
Product Release Notes
Latest Product Release Notes
-
Product Portfolio
-
Insights
- Ignite Webinar Series
-
Research Hub
Latest Insights
-
Industry Primers
Latest Insights
Industry Primer
Optimizing Sales Excellence: A Comprehensive Guide to Sales Performance Management
 Learn More
Learn More
-
Blogs & Infographics
Latest Insights
Blog
NexGen Commercial Intelligence: How Generative and Agentic AI are powering Field Force...
 Learn More
Learn More
Blog
Cell & Gene Therapies for Rare Diseases: Unlocking New Possibilities with Real-World Data
 Learn More
Learn More
-
Customer Success Stories
Latest Insights
Case Study
Building a Scalable Data Governance Foundation: The Modernization Journey of a Global...
 Learn More
Learn More
Case Study
Transforming Women's Health: Delivering High Accuracy with AI/ML-Driven Forecasting for...
 Learn More
Learn More
-
Podcasts & Videos
Latest Insights
-
Fact Sheets, Data Sheets & Guides
Latest Insights
Fact Sheet
Axtria DataMAx™ - Accelerate actionable business insights from trusted and secure data
 Download Fact Sheet
Download Fact Sheet
-
Media Wall
Latest Insights
Media Wall
Axtria Ignite 2025: Madhavi Ramakrishna on leadership, culture, and AI transformation |...
 Learn More
Learn More
Media Wall
What Does It Take to Scale AI for Impact Beyond Proofs of Concept : Panel Discussion With...
 Learn More
Learn More
Media Wall
What It Really Takes to Move AI Beyond the Pilot Phase: Insights from MachineCon NY
 Learn More
Learn More
-
Newsletter
March 2025
NexGen commercial intelligence, case study on transforming territory alignment, and more
 View Newsletter
View Newsletter
-
About
-
Our Story
Passionate people transforming patient lives
-
Business Sustainability

-
Culture
We are Individually diverse & collectively inclusive

-
Partnerships & Alliances
Delivering value through an ecosystem of partners

-
Careers
Connect with us – We’re ready to talk opportunities

-
Newsroom

-
Our Story















Contact Us
Axtria Inc. 300
Connell Drive, 5th & 6th Floor,
Berkeley Heights, NJ 07922
United States
+1-877-929-8742
connect@axtria.com
Copyright © 2025 Axtria. All Rights Reserved.
Axtria Cookie Policy & Privacy Statement.